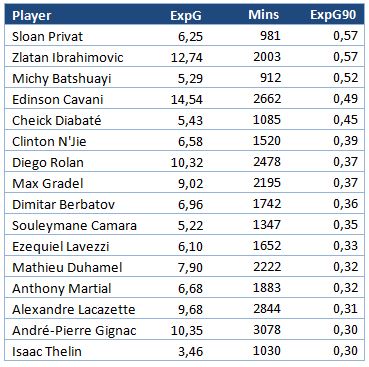
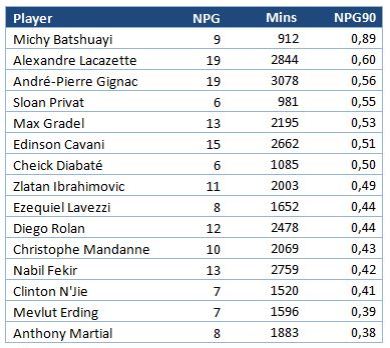
Note: All the work presented in this post has been done together with my friend Tim Jonsson and has been supervised by David Sumpter. This post does get a little technical but hopefully the points will come across regardless of the level of statistical knowledge of the reader 🙂
Any football fan can subjectively distinguish between different types of attacks while watching a game, but doing this for every single game in a season, potentially over several different leagues, would be practically impossible. Using data from OPTA on the 2015/2016 season of the English Premier League, we set out to investigate whether we could automatically categorize attack types, in a way that resembles how we would subjectively categorize them manually, using k-means clustering. We then took our clustering solution and used it in a logistic regression to investigate whether the attack type that led to the shot has an impact on the probability of the shot being converted into a goal.
Data preparation
Raw OPTA event data was used to identify chains of possession, i.e. an unbroken sequence in which a team is considered to be in possession of the ball. Next, only possession chains that led to a shot attempt were filtered out for analysis. 21 variables describing each ”shot chain” were then created. These variables include information such as the number of players involved in the chain, the length (in time) of the chain, the number of passes etc, and tries to quantitatively capture ways in which we think that different attack types differ from each other. In the end, once own goals had been filtered out, we ended up with a data set of roughly 9600 observations where each observation corresponds to a shot attempt taken in the 2015/2016 EPL.
Clustering
Before running the k-means clustering algorithm, Principal component analysis was applied to reduce the dimensionality in the data. Four principal components were retained for the clustering.
When using k-means clustering, one has to decide on the number of cluster before running the algorithm. We hypothesized that all attacks can be roughly divided into four attack types: Long possession spells, counter-attacks, counter-press and set-pieces. However, when running the algorithm using four clusters, the results were not exactly as hypothesized beforehand. The shots from various set pieces were spread out over different clusters, with penalties and direct free-kicks ending up in the same cluster, but shots from corners, throw-ins and non direct free-kicks ended up in another cluster. Furthermore, a specific cluster for shots from counter-pressing situations was not created. Instead, these shots were spread out between all other clusters apart from a cluster containing long possessions only. Finally, a separate cluster was not created for counter-attacks. Instead, various fast and short attacks were clustered together forming a cluster that can be labeled ”Direct play” rather than specifically counter-attacks.
In order to refine the cluster solution the analysis was performed using several different number of clusters. The solution that was deemed best uses six different clusters to categorize the attack types. This solution solves some of the previously acknowledged problems with the four cluster solution, as it does create a cluster for all counter-pressing actions that have at least one pass in the sequence before a shot is attempted. It also manages to separate counter-attacks (starting in a team´s own half) and other direct plays that are now usually categorized with counter-pressing actions, as should be the case. However, the solution still fails to separate free-kicks and penalties from shots taken immediately after a counter-pressing action.
There is some overlap in the clusters, a few observations that are in fact counter-pressing shots are clustered together with non-direct shot set pieces, but the general groups are quite clear and be seen in the table below (n = the number of observations in each cluster).

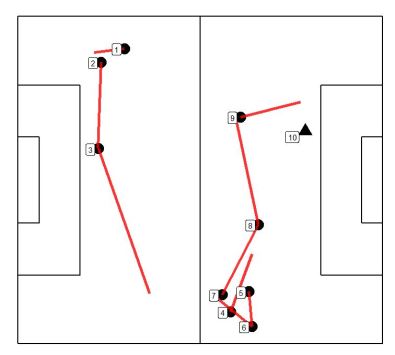
Below are plots showing one example attack from each attack type. Circles represent passes and triangle represents the shots, and the events are numbered by the order in which they occurred in real time. The lines show the paths of the passes. When there is a gap between the end location of a pass and the start location of the next event, a player might have moved with the ball, or any other action might have occurred that does not lead to the possession chain breaking with the definition used.
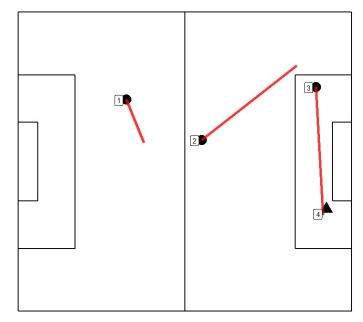
Cluster 1 -Counter-attacks
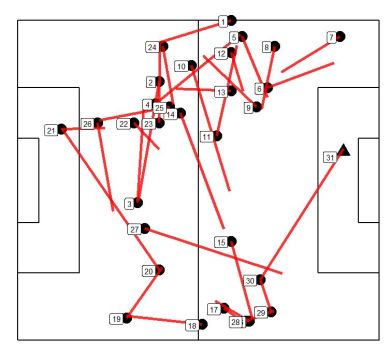
Cluster 2 – Very long possessions
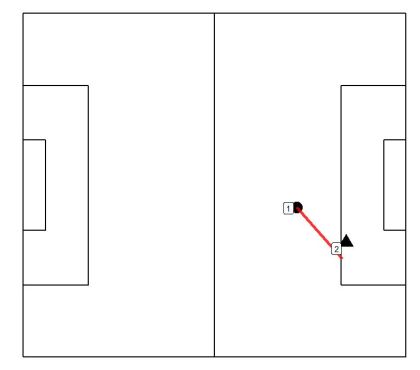
Cluster 3 – Immediate shots
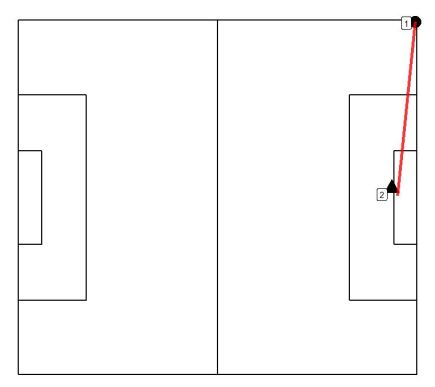
Cluster 4 – Long possessions
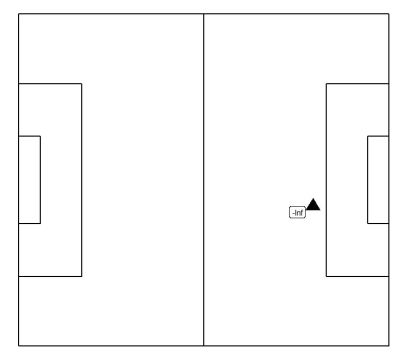
Cluster 5 – Counter-press
Cluster 6 – Non-direct shot set pieces
Effects of attack type on goal probability
To investigate whether different attack types creates chances of different quality a logistic regression was fitted to estimate the probability of a shot being converted into a goal using only information about the attack type that led up to the shot. The non-direct shot set pieces was used as the baseline level as this was the most common attack type. The coefficients from the regression (shown below) indicates that shots from counter-attacks, very long possessions and immediate shots are more likely to result in a goal as they have a positive sign and are significant at 5% significance level, compared to the shots from non-direct shot set pieces.
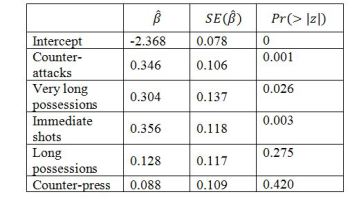
When controlling for location by including information about the distance and angle towards goal, all coefficients for attack types were positive and significant at 5% significance level. This indicates that given the same location, shots from non-direct shot set pieces are less likely to result in a goal.
Next we fitted yet another model using information about the location, attack type as well as contextual information from the raw data about each shot to more accurately model the probability of a shot being converted into a goal. The distribution of goal probability per shot, by cluster is plotted below, as is the mean and standard deviation of goal probability for each cluster.
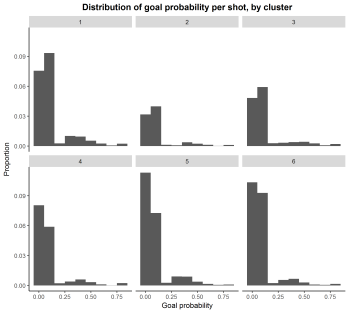
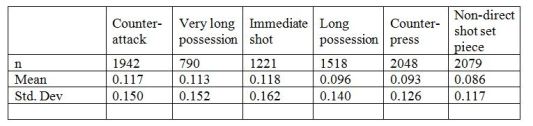
Finally, the non-parametrical Kruskal-Wallis and Dunn´s test were ran to investigate if there is any differences in the quality of chances created between all clusters, with results similar to those obtained from the logistic regression. Shots from counter-attacks, very long possessions and immediate shots are significantly more likely to result in a goal than shots from long possessions, counter-press and non-direct shot set pieces, but there are no sigificant differences in average goal probability within these two larger ”groups of groups”, so to speak.
Conclusion
Is it possible to automatically categorize attack types fraom data only using k-means clustering?
For the most part, yes, especially open play attack types. This method could potentially be used to scout teams and players from wherever we have data to get an understanding of how often a team uses a specific attack type and often different players participate in different attack types.
Do different attack types create different quality chances?
Yes. There is a significant difference in the quality of shot attempts generated from different attack types, at least during the EPL 2015/2016 season. It would be very interesting to see if the same conclusions hold over multiple leagues and seasons.